[TOC]
本文是把《Kubernetes In Action》读薄的摘抄或转述,仅供参考。系统学习请阅读原书。
k8s的命令繁多,熟练使用它们提高工作效率和理解k8s设计思想同等重要,每章最后总结了该章涉及的命令。

2019~2020年期间,在工作上使用过Kubernetes(k8s)+Istio治理微服务。我们的业务是做一个Iass+Paas平台,我们把计算、网络、存储、安全、数据库、负载均衡和监控等模块拆分成微服务,每个服务在一组相同的pod运行,每个pod中运行两个容器,业务容器和sidecar。Istio Ingress作为k8s的Ingress Controller,用于对外暴露服务,并且管理南北向流量。Istio的sidecar注入pod,用于管理集群内服务之间的东西向流量。
当时我只是在项目中应用了istio+k8s,没有系统学习过k8s,包括它的设计思想。最近因为工作再次接触k8s,于是挑选了《Kubernetes In Action》进行系统学习和温故而知新,这确实是一本不多见的涵盖广阔提纲挈领的好书。
微服务架构,它从管理上获取对服务的抽象,方便服务的管理和规划服务的边界。但它因为引入了很多新的机制,比如服务注册中心等,其实对硬件而言是一种牺牲。但舍弃一定的性能,换来的是服务的治理、团队协作开发的方便,这就是微服务架构的价值。
程序的本质从不同角度观察,会有不同的见解,就像光的波粒二象性。我的观点是不浪费硬件是对提升性能最大的帮助。会有听到微服务解决了高并发问题的说法,但微服务和高并发其实没有必然关系。而是因为通常微服务会使用分布式方式部署,硬件资源包括CPU、网络、磁盘等成倍增加,所以分布式对高并发问题有积极作用。
Istio,它其实不局限于微服务治理范畴,任何服务,只要服务间有访问,需要对服务间的流量进行管理、服务间认证等,都可以使用Istio来管理。
k8s不是一个专为Docker设计的容器编排系统。k8s的核心也不止是编排容器,只不过容器恰好是在不同集群节点上运行应用的最佳方式。k8s可以被看作集群的一个操作系统,提供服务发现、扩容、负载均衡、自恢复、leader选举等功能。
1 Kubernetes 介绍 1
微服务架构是替代以单个进程或几个进程运行在服务器上为部署方式的单体应用的一种方式,它将单体应用分解成若干个可独立运行组件。微服务的解耦性,确保它们可以被独立开发、部署、升级、伸缩。
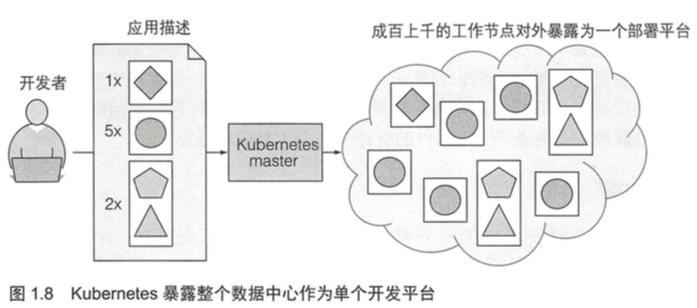
如何部署、管理这些微服务,并充分利用宿主机的硬件资源,诞生了k8s。k8s可以理解为是一个数据中心操作系统(DCOS),他将人员分为开发人员和系统管理员,系统管理员负责处理和硬件、集群相关的事务,开发人员只需要提交自己的应用和描述。k8s会「自动」按照开发人员的描述,把应用启动起来,并暴露定义的端口。
在computer science领域,有一句话”All problems in computer science can be solved by another level of indirection”。k8s抽象了数据中心的硬件基础设置,对外暴露资源池API,开发人员不用关心底层的硬件设施。这种抽象和操作系统也有相似之处。
1.1 Kubernetes 系统的需求 2
1.1.1 从单体应用到微服务 2
对于单体应用,为了提升系统负载能力,有两种扩展方式。
垂直扩展:增加CPU、内存或其它系统资源。应用程序无需变化,但成本越来越高,无法无限扩展。
水平扩展:经常需要应用程序进行改动才可执行,可能会被某个模块无法水平扩展限制。
单体应用可被拆分成多个可独立部署、以独立进程运行的微服务,微服务之间以约定的API通信。
对于微服务架构,可以只扩容某些服务,因为扩容粒度细化,可以根据具体情况分配扩容资源。
如果有历史项目是单体应用,不得不水平扩容,而水平扩容受到某些模块的限制。可以把应用拆分成多个微服务,对能扩容的组件水平扩展,对不能扩容的组件垂直扩展。
看似一切很美好,微服务带来的弊端不容忽视。
当服务数量激增,如何处理服务间错综复杂的依赖关系,如何把正确的配置应用到每个服务,如何调试代码和定位异常调用,如何解决不同服务对于环境需求的差异,都是需要面对的。
1.1.2 为应用程序提供一个一致的环境 5
目标是让服务在开发和生产阶段可以运行在完全一样的环境下,有完全一样的操作系统、库、系统配置、网络环境等。各个服务之间独立互不影响。
1.1.3 迈向持续交付 :DevOps 和无运维 6
让应用开发者和系统管理员解耦,开发者可以自己参与配置和部署程序,但又无需关注硬件基础设施。而实际上系统管理员在幕后保证底层基础设施正常运转,但他们也无需关注运行的程序本身。
这正是k8s实现的功能。它对硬件资源进行抽象,对外暴露成一个平台,用于部署和运行应用程序。
1.2 介绍容器技术 7
k8s使用Linux容器技术来实现对应用的隔离。
1.2.1 什么是容器 7
虚拟机可以隔离不同的微服务环境是显然的,Linux容器技术也可以。容器和虚拟机相比开销小很多,容器里运行的进程实际上运行在宿主机上,但是和其它进程隔离,开销仅是容器消耗的资源。
虚拟机和容器中的应用进程对CPU的使用方式不同。每个虚拟机对应的Linux内核不一样,而不同容器对应的Linux内核一样(存在安全隐患)。如图所示。
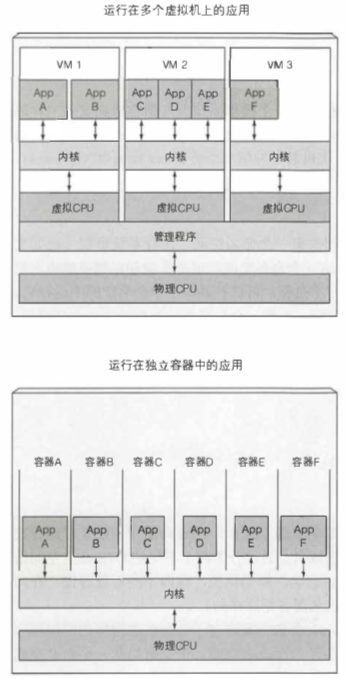
如果多个进程运行在同一个操作系统上,是怎么利用容器是隔离它们的?有两个机制可用。
- Linux命名空间。可以在某个命名空间运行一个进程,进程只能看到这个命名空间下的资源。当然,会存在多种类型的命名空间,所以一个进程不单单只属于某一个命名空间,而属于每个类型的一个命名空间。
存在以下类型的命名空间:
- Mount(mnt)
- Process ID(pid)
- Network(net)
- Inter-process communicaion(ipd)
- UTS
- User ID(user)
- 内核的cgroups。限制进程能使用的资源量(CPU、内存、网络带宽等)不能超过被分配的量。
1.2.2 Docker 容器平台介绍 11
Docker是第一个使容器成为主流的容器平台。Docker本身不提供进程隔离,而是由Linux命名空间和cgroups之类的内核特性完成。
镜像层是只读的。容器运行时,一个新的可写层在镜像层之上被创建。 容器中进程写入位于底层的一个文件时,此文件的一个拷贝在顶层被创建,进程写的是此拷贝。
Docker可以借助于镜像在不同操作系统之间移植,但是内核由运行容器的宿主机决定。如果一个容器化的应用需要一个特定的内核版本,那它可能不能在每台机器上都工作。 如果一台机器上运行了一个不匹配的 Linux 内核版本,或者没有相同内核模块可用,那么此应用就不能在其上运行。所以容器镜像存在移植性的限制,在不同CPU架构上构建的镜像不能通用。例如在x86平台构建的镜像,不能在arm平台使用。
1.2.3 rkt——一个 Docker 的替代方案 14
开放容器计划OCI是围绕容器格式和运行时创建的开放工业标准。kubelet以CRI标准接口与OCI进行通信。rkt是另一个Linux容器引擎。
本书集中使用Docker作为k8s的容器,它是k8s最初唯一支持的容器类型,但k8s目前也支持rkt等其它容器类型。
1.3 Kubernetes 介绍 15
1.3.1 初衷 15
在海量服务器规模下,有效处理部署管理,并提高基础设施利用率。
1.3.2 深入浅出地了解 Kubernetes 15
k8s整个系统由一个主节点和若干个工作节点组成。开发者把一个应用列表提交到主节点,k8s会将它们部署到集群的工作节点。组件被部署在哪个节点对于开发者和系统管理员来说都不用关心 。开发者能指定一些应用必须一起运行,k8s将会在一个工作节点上部署它们。其他的将被分散部署到集群中,但是不管部署在哪儿,它们都能以相同的方式互相通信。
1.3.3 Kubernetes 集群架构 17
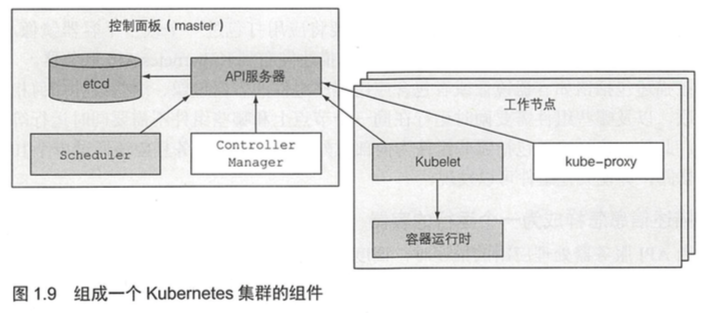
一个k8s集群由很多节点组成,分为两种类型:
- 主节点:它承载着k8s控制和管理整个集群系统的控制面板。控制面板的组件持有井控制集群状态,但是它们不运行应用,运行应用是由工作节点完成的。
- API服务器:应用和其它控制面板组件都要和它通信。
- Scheculer:调度应用(为应用的每个可部署组件分配一个工作节点)。
- Controller Manager:执行集群级别的功能,如复制组件、持续跟踪工作节点、处理节点失败等。
- etcd:一个可靠的分布式数据存储,它能持久化存储集群配置。
- 工作节点:它们运行用户实际部署的应用。
- Docker、rkt或其它容器类型。
- Kubelet:与API服务器通信,并管理它所在节点的容器。
- kube-proxy:负责组件之间的负载均衡网络流量。
1.3.4 在 Kubernetes 中运行应用 18
在向k8提交描述符之后,它将把每个pod的指定副本数量调度到可用的工作节点上。 节点上的 Kubelets将告知Docker从镜像仓库中拉取 容器镜像井运行容器。
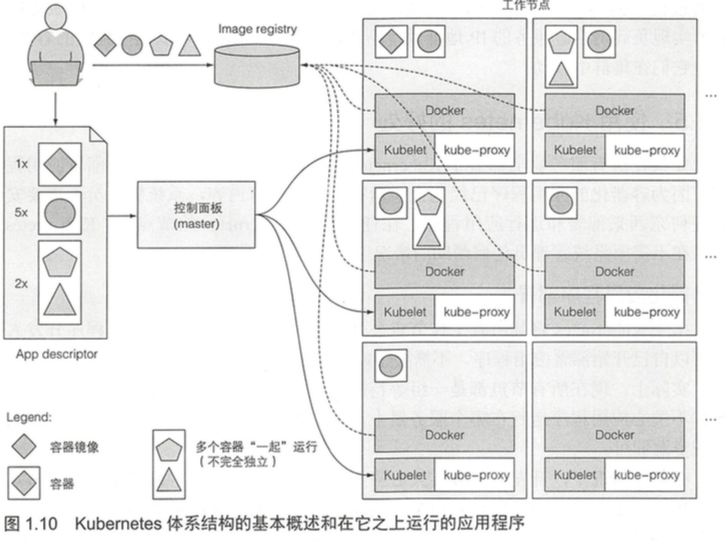
一旦应用程序运行起来,k8s就会不断地确认应用程序的部署状态始终与你提供的描述相匹配。
k8s采用声明式的控制流,所有的资源声明都保存在etcd,所有的组件都通过API Server来声明或监听资源。只要资源被声明,那么监听资源的控制器就会开始工作,确保让各个资源实例达到声明的状态。
1.3.5 使用 Kubernetes 的好处 20
- 简化应用程序部署
- 更好地利用硬件
- 健康检查和自修复
- 自动扩容
- 敏捷交付
2 开始使用 Kubernetes 和 Docker 23
2.1 创建、运行及共享容器镜像 23
容器中的进程是运行在主机操作系统上的,但是该进程的ID在主机上和容器中不同。容器使用独立的PID Linux命令空间并且有着独立的系列号,完全独立于进程树。
正如拥有独立的进程树一 样,每个容器也拥有独立的文件系统。在容器内列出 根目录的内容,只会展示容器内的文件,包括镜像内的所有文件,再加上容器运行时创建的任何文件(类似日志文件)。
使用是比较简单的,本文不赘述了。
2.2 配置 Kubernetes 集群 34
主要讲如何创建k8s集群,讲了两个方法:用 Minikube 运行一个本地单节点 Kubernetes 集群;用 Google Kubernetes Engine 托管 Kubernetes 集群。以及为kubectl 配置别名和命令行补齐,方便命令输入。
使用是比较简单的,本文不赘述了。
2.3 在 Kubernetes 上运行第一个应用 40
2.3.1 部署 Node.js 应用 40
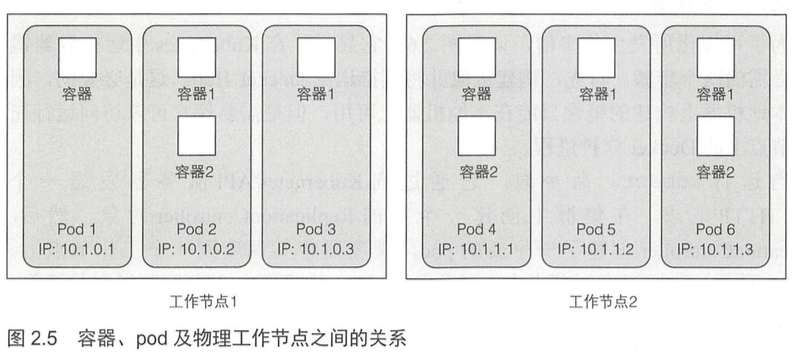
一个pod是一组紧密相关的容器,它们总是一起运行在同一个工作节点上,以及同一个Linux命名空间中。每个pod就像一个独立的逻辑机器,拥有自己的IP、主机名、进程等,运行一个独立的应用程序。应用程序可以是单个进程,运行在单个容器中,也可以是一个主应用进程或者其他支持进程,每个进程都在自己的容器中运行。一个pod的所有容器都运行在同一个逻辑机器上,而其它pod中的容器,即使运行在同 一个工作节点上,也会出现在不同的节点上 。
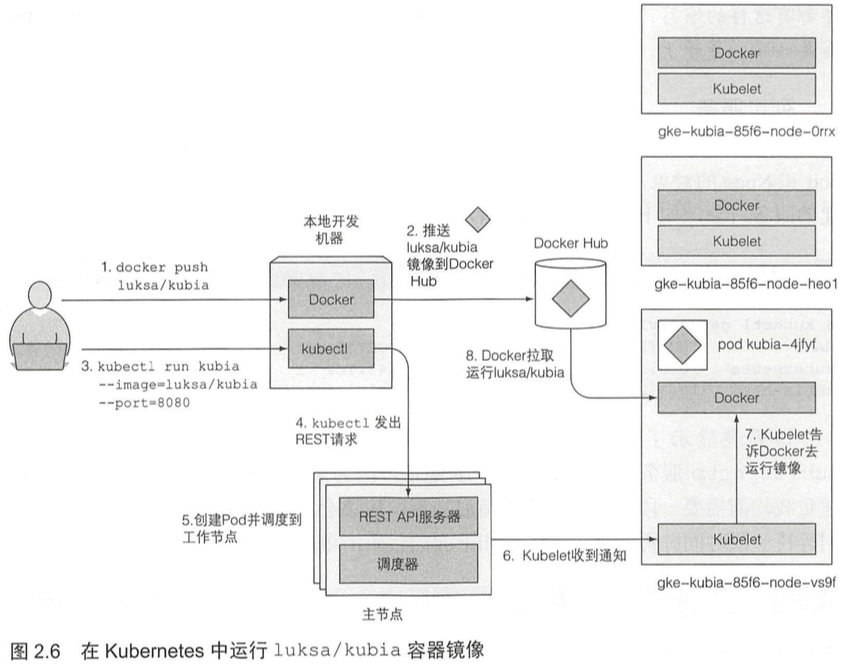
当运行kubectl命令时,它通过向API服务器发送一个REST HTTP请求,在集群中创建一个新的ReplicationController对象。然后,ReplicationController创建了一个新的pod,调度器将其调度到 一个工作节点上。Kubelet看到pod被调度到节点上,就告知Docker从镜像中心中拉取指定的镜像,因为本地没有该镜像。下载镜像后,Docker创建并运行容器。
2.3.2 访问 Web 应用 43
每个pod有自己的IP地址,但是这个地址是集群内部的,不能从集群外部访问。要让pod能够从外部访问,需要通过服务对象公开它,要创建一个LoadBalancer类型的服务。它将创建一个外部的负载均衡,外部可以通过负载均衡的公共IP访问pod。
2.3.3 系统的逻辑部分 45
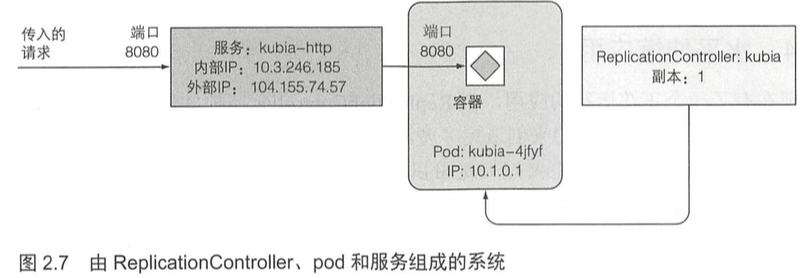
k8s的基本构件是pod,但是没有直接创建和使用pod。通过运行kubectl run命令,创建了一个ReplicationController,它用于创建pod实例 。为了使该pod能够从集群外部访问,需要让 k8s将 该ReplicationController管理的所有pod由一个服务对外暴露。服务表示一组或多组提供相同服务的pod的静态地址。到达服务IP和端口的请求将被转发到属于该服务的一个容器的IP和端口。
2.3.4 水平伸缩应用 46
为了增加pod的副本数,需要改变ReplicationController期望的副本数。告诉k8s需要确保pod始终有三个实例在运行。成功后,请求会随机地切到不同的pod。
应用本身需要支持水平伸缩。
没有告诉k8s需要采取什么行动,也没有告诉k8s增加两个pod,只设置新的期望的实例数量并让 k8s决定需要采取哪些操作来实现期望的状态。这是k8s最基本的原则之一。不是告诉 k8s 应该执行什么操作,而是声明性地改变系统的期望状态,并让k8s检查当前的状态是否与期望的状态一致。在整个 k8s 世界中都是这样的——声明式设计。
2.3.5 查看应用运行在哪个节点上 49
不管调度到哪个节点,容器中运行的所有应用都具有相同类型的操作系统。每个pod都有自己的IP,并且可以与任何其他pod通信,不论其他pod是运行在同一 个节点上,还是运行在另一个节点上。每个pod都被分配到所需的计算资源,因此这些资源是由一个节点提供还是由另一个节点提供,并没有任何区别。
2.3.6 介绍 Kubernetes dashboard 50
k8s的图形化用户界面。列出部署在集群中的所有pod、ReplicationController、服务和其他部署在集群中的对象, 以及创建、修改和删除它们。
2.4 本章的k8s命令
1 | ########## 集群 ########## |
3 pod :运行于 Kubernetes 中的容器 53
pod是k8s中最重要的核心概念,而其他对象仅仅是在管理、 暴露pod或被pod使用。
3.1 介绍 pod 53
当一个 pod包含多个容器时,这些容器总是运行于同一个工作节点上。一个pod绝不会跨越多个工作节点。
3.1.1 为何需要 pod 54
容器被设计为每个容器只运行一个进程(除非进程本身产生子进程)。如果在单个容器中运行多个不相关的进程,那么保持所有进程运行、管理它们的日志等将会是我们的责任。例如,我们需要包含一种在进程崩溃时能够自动重启的机制。同时这些进程都将记录到相同的标准输出中, 而此时我们将很难确定每个进程分别记录了什么。
我们需要让每个进程运行于自己的容器中,而这就是Docker和k8s期望使用的方式。
pod是k8s调度的最小单位,一个 pod可以包含一个或多个容器。
3.1.2 了解 pod 55
由于不能将多个进程聚集在一个单独的容器中,我们需要另一种更高级的结构来将容器绑定在一 起,并将它们作为一个单元进行管理,这就是pod背后的根本原理。
k8s通过配置Docker来让一个pod内的所有容器共享相同的Linux命名空间,而不是每个容器都有自己的一组命名空间。
由于一个pod中的所有容器都在相同的network和UTS命名空间下运行,所以它们都共享相同的主机名和网络接口。 同一个pod中的容器共享相同的IP地址和端口空间。同样地,这些容器也都在相同的IPC命名空间下运行,因此能够通过IPC进行通信。在最新的k8s和Docker版本中,它们也能够共享相同的PID命名空间(但是该特征默认是未激活的)。
k8s集群的pod之间没有NAT网关,两个pod彼此之间发送网络数据包时,它们都会将对方的实际IP地址看作数据包中的源IP。
3.1.3 通过 pod 合理管理容器 56
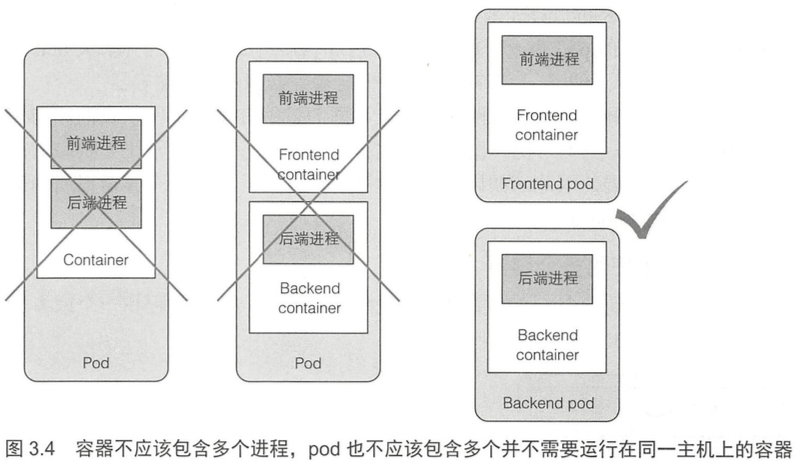
当决定是将两个容器放入一个pod还是 两个单独的pod时,我们需要问自己以下问题:
- 它们需要 一起运行还是可以在不同的主机上运行?
- 它们代表的是一个整体还是相互独立的组件?
- 它们必须一起进行扩缩容还是可以分别进行?
我们总是应该倾向于在单独的pod中运行容器,除非有特定的原因要求它们是同一pod的一部分。
比如常见的是sidecar容器,用于日志轮转器和收集器、数据处理器、通信适配器等。
在实际业务场景中,在pod中使用多个容器,sidecar是最常见的方式。其它情况,需要三思。
3.2 以 YAML 或 JSON 描述文件创建 pod 58
pod和其它k8s资源通常是通过向k8s REST API提供JSON或YAML描述文件来创建的。
全面的文档在Kubernetes API参考文档。
3.2.1 检查现有 pod 的 YAML 描述文件 59
pod定义由这几个部分组成:首先是YAML中使用的k8s API版本和YAML描述的资源类型;其次是几乎在所有k8s资源中都可以找到的三大重要部分:
- metadata:包括名称、命名空间、标签和关于该容器的其他信息。
- spec:包含pod内容的实际说明,例如pod的容器、卷和其他数据。
- status:包含运行中的pod的当前信息,例如pod所处的条件、 每个容器的描述和状态,以及内部IP和其他基本信息。status只包含只读的运行时数据,在创建新的pod时,不需要提供status部分。
3.2.2 为 pod 创建一个简单的 YAML 描述文件 61
一个基本的pod描述文件非常简单。
1 | apiVersion: v1 |
3.2.3 使用 kubectl create 来创建 pod 63
kubectl create -f命令用于从YAML或JSON文件创建任何资源。创建后可以请求k8s获得完整的YAML和JSON格式的描述文件。
3.2.4 查看应用程序日志 64
当日志文件达到一定大小时,容器日志会自动轮替。kubectl logs命令仅显示最后一次轮替后的日志条目。
当一个pod被删除时,它的日志也会被删除。如果希望在pod删除之后仍然可以获取其日志,我们需要设置中心化的、集群范围的日志系统,将所有日志存储到中心存储中。
3.2.5 向 pod 发送请求 65
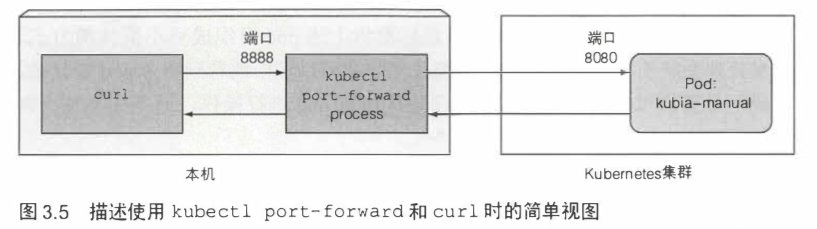
如果要在外部访问pod,除了前面提到的lb service,还可以借助端口转发(常用于开发中测试pod)。端口转发通过kubectl port-forward命令完成。
3.3 使用标签组织 pod 66
通过一次操作对属于某个组的所有pod进行操作,而不必单独为每个pod执行操作。
标签可以做到这一点。通过标签来组织pod和所有其他k8s对象。
3.3.1 介绍标签 66
标签是可以附加到资源的任意键值对。通过标签选择器可以选择具有确切标签的资源。
标签和资源是多对多关系。
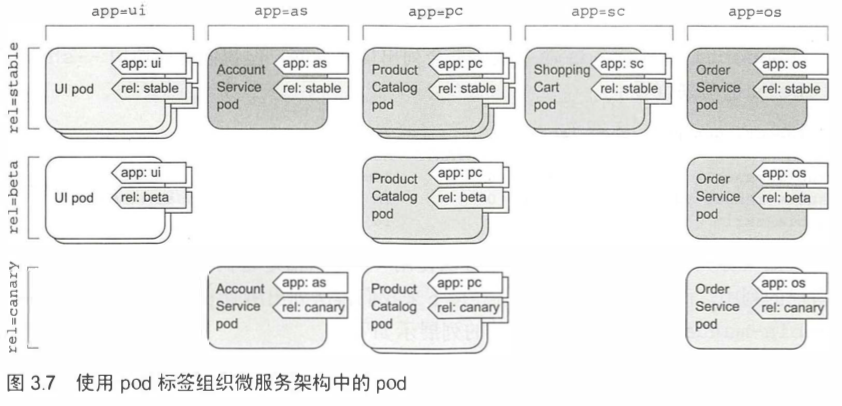
比如常用的场景有,给每个pod标有两个标签。
- app:它指定pod属于哪个应用、 组件或微服务。
- rel:它显示在pod中运行的应用程序版本是stable、beta还是canary(用于金丝雀发布)。
3.3.2 创建 pod 时指定标签 67
包含creation_method=manual,env=prod两个标签。
1 | ... |
3.3.3 修改现有 pod 的标签 68
标签可以在现有pod上进行添加和修改。
3.4 通过标签选择器列出 pod 子集 69
标签要与标签选择器结合,否则标签没有作用。
3.4.1 使用标签选择器列出 pod 69
标签选择器根据资源的以下条件来选择资源:
- 包含(或不包含)使用特定键的标签。
- 包含具有特定键和值的标签。
- 包含具有特定键的标签,但其值与我们指定的不同。
3.4.2 在标签选择器中使用多个条件 71
在包含多个逗号分隔的清况下,可以在标签选择器中同时使用多个条件。 此时,资源需要全部匹配才算成功匹配了选择器。
3.5 使用标签和选择器来约束 pod 调度 71
在硬件基础设施不是同质的情况下,比如想将执行GPU密集型运算的pod调度到提供GPU加速的节点上,需要约束pod的调度。这可以通过节点标签和节点标签选择器完成。
3.5.1 使用标签分类工作节点 72
pod并不是唯一可以附加标签的k8s资源。标签可以附加到任何k8s对象上,包括节点。
3.5.2 将 pod 调度到特定节点 72
在spec部分添加了一个nodeSelector字段。当创建该pod时,调度器将只在包含标签gpu=true的节点中选择。
1 | ... |
3.5.3 调度到一个特定节点 73
也可以将pod调度到某个确定的节点,由于每个节点都有一个唯一标签,其中键为kubernetes.io/hostname, 值为该节点的实际主机名, 因此也可以将pod调度到某个确定的节点。但如果节点处于离线状态,通过hostname标签将nodeSelector设置为特定节点可能会导致pod不可调度。所以绝不应该考虑单个节点,而是应该通过标签选择器考虑符合特定标准的逻辑节点组。
3.6 注解 pod 73
pod和其它对象还可以包含注解。注解也是键值对。但是注解不能像标签一样用于对对象分组。不存在注解选择器这样的东西。
3.6.1 查找对象的注解 74
注解可以包含相对更多的数据,标签则是应该比较简短的。
3.6.2 添加和修改注解 74
通过kubectl annotate命令添加和修改注解。
3.7 使用命名空间对资源进行分组 75
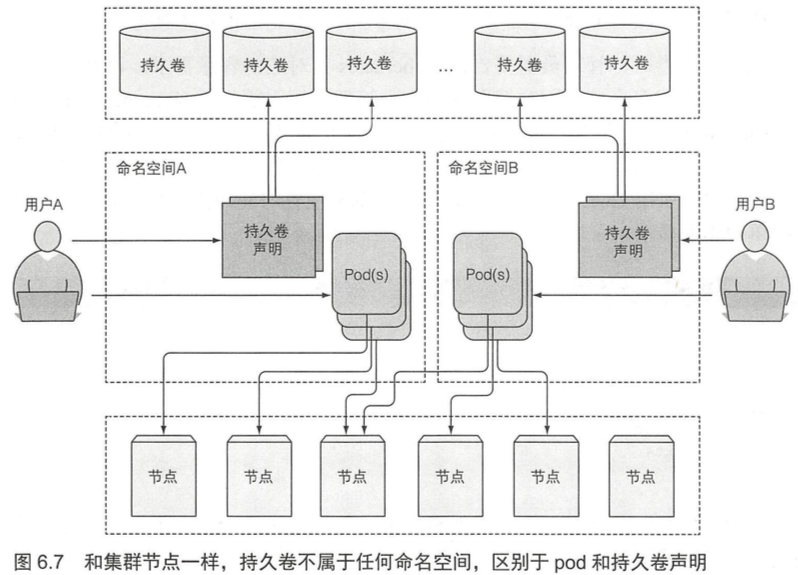
k8s中可供声明的类称为资源(Resource),包括 pod、rs、deployment 等。声明一个资源构成的实例都有名字,这些名字都归属于一个个的命名空间之中(namespace),互不影响。
3.7.1 了解对命名空间的需求 75
在使用多个namespace的前提下,可以将包含大量组件的复杂系统拆分为更小的不同组,这些不同组也可以用于在多租户环境中分配资源,将资源分配为生产、开发和QA环境。两个不同命名空间可以包含同名资源。
我们在业务上也这样使用过,为了减小硬件开销,开发和QA环境使用同一套k8s集群,使用不同的namespace区分。
3.7.2 发现其他命名空间及其 pod 75
命名空间除了为资源名称提供了一个作用域,也可用于仅允许某些用户访问某些特定资源,甚至限制单个用户可用的计算资源数量。
3.7.3 创建一个命名空间 76
k8s中的所有资源都是一个API对象。命名空间同理,所以创建namespace也可以用YAML文件描述,使用kubectl create -f xxx.yaml创建。
1 | apiVersion: v1 |
也可以通过kubectl create namespace命令创建。
3.7.4 管理其他命名空间中的对象 77
在列出、描述、创建、修改、删除等操作中,需要给kubectl命令传递--namespace。否则kubectl在当前上下文中配置的默认命名空间执行操作。
当前上下文的命名空间可以通过kubectl config修改。要想快速切换到不同的命名空间,可以设置以下别名:alias kcd='kubectl config set-context $(kubectl config current-context) --namespace'。然后使用kcd some-namespace在命名空间之间进行切换。
3.7.5 命名空间提供的隔离 78
你需要首先创建命名空间,然后再创建资源。
k8s 包含三个预设的命名空间:
- default
- kube-public
- kube-system
命名空间之间是否网络隔离依赖于k8s使用的NetworkPolicy的配置。
3.8 停止和移除 pod 78
3.8.1 按名称删除 pod 78
在删除pod的过程中,实际上我们指示k8s终止该pod中的所有容器。k8s会向进程发送SIGTERM信号并等待一定时间,使其正常关闭(所以为了确保进程能正常关闭,业务代码中需要处理SIGTERM信号)。如果没有及时关闭,k8s则通过发送SIGKILL终止该进程。
3.8.2 使用标签选择器删除 pod 79
可以使用标签一次删除所有指定标签的pod。
3.8.3 通过删除整个命名空间来删除 pod 80
删除整个命名空间,pod将也会自动删除。
3.8.4 删除命名空间中的所有 pod,但保留命名空间 80
要删除pod,还需要删除ReplicationController,否则会根据YAML描述文件自动创建新的pod。因为k8s是声明式设计。
3.8.5 删除命名空间中的(几乎)所有资源 80
--all删除所有内容并不是真的删除所有内容,一些资源例如secret会被保留下来,除非明确指定删除。
3.9 本章的k8s命令
1 | ########## 查看pod ########## |
4 副本机制和其他控制器 :部署托管的 pod 83
前三章比较基础,从这一章开始,事情变得有趣起来。
通过创建ReplicationControlle或Deployment这样的资源,由它们来创建并管理实际的pod。kubelet会保持该节点上的pod健康。
4.1 保持 pod 健康 84
4.1.1 介绍存活探针 84
k8s可以通过存活探针(liveness probe)检查容器是否还在与进行。可以为pod中的每个容器单独指定存活探针,如果探测失败,k8s将定期执行探针并重新启动容器。
k8s有三种探测容器的机制(在spec内定义livenessProbe):
- HTTP GET 探针:是否能正确响应GET请求。
- TCP 探针:是否能建立TCP连接。
- exec 探针:在容器内执行指定命令并检查退出状态码。
4.1.2 创建基于 HTTP 的存活探针 85
1 | ... |
4.1.3 使用存活探针 86
通过kubectl describe查看为什么必须「重启」容器。不是真的重启,是创建一个新的容器。
Exit Code的值减去128是终止进程的信号编号。比如Exit Code是137,表示因为SIGKILL(9)信号被终止。
4.1.4 配置存活探针的附加属性 87
其它属性,包括delay、timeout、period等。
例如可用initialDelaySeconds自定义初始延迟。务必记得设置一个初始延迟来说明应用程序的启动时间。否则容器可能不断被重启。
1 | ... |
4.1.5 创建有效的存活探针 88
一定要检查应用程序的内部,而没有外部因素的影响,比如不能调用在其它pod的数据库容器。并且保证存活探针轻量,也无需在探针中实现重式循环。
4.2 了解 ReplicationController 89
ReplicationController已经完全被ReplicaSet替代,阅读了一下但不再赘述。
4.3 使用 ReplicaSet 而不是 ReplicationController 104
通常不会直接创建ReplicaSet,而是通过在创建Deployment资源(在后面章节讲)时创建。
4.3.1 比较 ReplicaSet 和 ReplicationController 104
ReplicaSet的标签选择器的表达能力比ReplicationController更强。
4.3.2 定义 ReplicaSet 105
ReplicaSet不是v1 API的一部分,但属于apps API组的v1beta2版本。
1 | apiVersion: apps/v1beta2 |
4.3.3 创建和检查 ReplicaSet 106
使用kubectl create命令根据YAML文件创建ReplicaSet。
4.3.4 使用 ReplicaSet 的更富表达力的标签选择器 106
rs和rc相比最大的改动就是支持更为强大复杂的标签选择器。
1 | selector: |
可以在selector中使用matchExpressions,支持的operator有:
- In:pod的label在指定labels之中。
- NotIn:不在指定labels中。
- Exists:指定的label key存在。
- DoesNotExist:指定的label key不存在。
如果你指定了多个表达式,则所有这些表达式都必须为true才能使选择器与pod匹配。如果同时指定matchLabels和matchExpressions,则所有标签都必须匹配,并且所有表达式必须计算为true以使该pod与选择器匹配。
4.3.5 ReplicaSet 小结 107
删除ReplicaSet会删除所有的pod。
4.4 使用 DaemonSet 在每个节点上运行一个 pod 107
4.4.1 使用 DaemonSet 在每个节点上运行一个 pod 108
使用DaemonSet在每个节点上运行一个pod。一般用于运行一些基础组件,如kube-proxy、日志组件等。
DaemonSet没有期望的副本数的概念,它的工作是确保一个pod匹配它的选择器并在每个节点上运行。如果节点下线,DaemonSet不会在其它地方重新创建pod。但是当一个新节点加入到集群中,DaemonSet会立即部署一个新的pod实例。
4.4.2 使用 DaemonSet 只在特定的节点上运行 pod 109
通过pod模板中的nodeSelector属性指定。
1 | apiVersion: apps/v1beta2 |
4.5 运行执行单个任务的 pod 112
前面提到的ReplicationController、ReplicaSet、DaemonSet都会持续运行任务,永远达不到完成态。k8s通过Job资源提供了可完成任务的支持,其进程正常终止后,不重新启动。
4.5.1 介绍 Job 资源 112
Job可以调度pod来运行一次性的任务,程序运行成功退出后,不重启容器。一旦任务完成,pod就被认为处于完成状态。
如果pod在被调度的节点上异常退出后,由Job管理的pod会一直被重新安排,直到成功完成任务。
4.5.2 定义 Job 资源 113
重启策略restartPolicy默认为Always。Job pod不能使用默认策略。需要明确将其设置为OnFailure或Never。
1 | apiVersion: batch/v1 |
4.5.3 看 Job 运行一个 pod 114
完成后的pod STATUS是Completed,并且不被删除。除非手动删除pod,或者删除创建它的Job。
4.5.4 在 Job 中运行多个 pod 实例 114
通过在Job配置中设置completions和parallelism属性,可以以并行或串行方式运行多个pod。
- 顺序运行Job pod
1 | apiVersion: batch/v1 |
- 并行运行Job pod
1 | apiVersion: batch/v1 |
通过kubectl scale命令更改parallelism属性,Job可以在运行过程中被缩放。
4.5.5 限制 Job pod 完成任务的时间 116
通过activeDeadlineSeconds属性,限制pod运行的时间。
通过spec.backoffLimit属性,配置Job在被标记为失败之前可以重试的次数。默认为6。
4.6 安排 Job 定期运行或在将来运行一次 116
k8s用CronJob资源设置cron任务。
4.6.1 创建一个 CronJob 116
CronJob通过jobTemplate模板创建资源。
1 | apiVersion: batch/v1beta1 |
4.6.2 了解计划任务的运行方式 118
在计划的时间内,CronJob资源会创建Job资源,然后Job创建pod。
可以通过指定CronJob规范中的startingDeadlineSeconds字段来指定截止时间。
CronJob总是为计划中配置的每个执行创建一个Job,但可能会同时创建两个Job,或者根本没有创建。为了解决第一个问题,你的任务应该是幂等的(多次而不是一次运行不会得到不希望的结果)。对于第二个问题,请确保下一个任务运行完成本应该由上一次的(错过的)运行完成的任何工作。
4.7 本章的k8s命令 118
1 | ########## 日志 ########## |
5 服务 :让客户端发现 pod 并与之通信 121
pod会在node间被调度,一组功能相同的pod需要对外提供一个稳定地址,而service就是pod对外的门户。
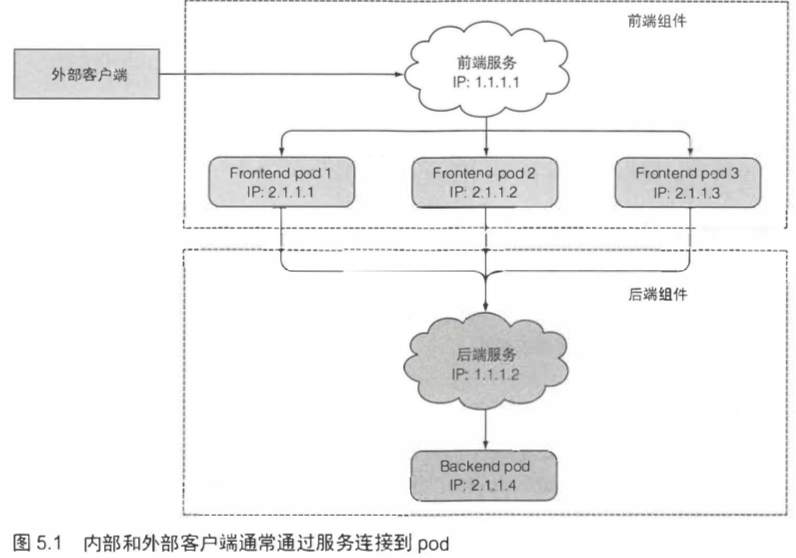
5.1 介绍服务 122
service会通过selector绑定多个pod,service通过clusterIP对外接收请求,然后分配给绑定的pod。
5.1.1 创建服务 123
通过kubectl expose命令或者YAML文件描述创建service均可。
例如创建一个名叫kubia的service。它将在端口80接收请求并将连接路由到具有标签选择器app=kubia的pod的8080端口上。
1 | apiVersion: v1 |
kubectl exec命令可以在一个存在的pod中运行命令。
如果希望特定客户端产生的所有请求每次都指向同一个 pod,可以设置服务的sessionAffinity属性为ClientIP。
k8s仅仅支持两种形式的会话亲和性服务: None 和 ClientIP。默认值None。
1 | ... |
k8s服务不是在HTTP层工作,服务处理TCP/UDP包,并不关心包的内容,所以k8s不支持基于cookie(HTTP协议的一部分)的会话亲和性选项。
同一个服务可以暴露多个端口,但必须给每个端口指定名字。标签选择器应用于整个服务,不能对每个端口做单独的配置。
1 | apiVersion: v1 |
可以在pod中定义port的名称,这样可以在service中按名称引用这些端口。
1 | kind: pod |
5.1.2 服务发现 129
在服务后面的pod可能删除重建,它们的IP地址可能改变,数量也会增减,但是始终可以通过服务的单一不变的IP地址访问到这些pod。
- 可以通过环境变量获取服务IP地址和端口号。
- 可以通过DNS发现服务(推荐)。但是客户端必须知道服务的端口号。
service的DNS地址为<service_name>.<namespace>.svc.cluster.local。svc.cluster.local是在所有集群本地服务名称中使用的可配置集群域后缀,可以省略。
k8s有一个kube-dns的pod,作为集群的DNS服务。集群中的其它pod都被配置成使用其作为DNS服务器(通过修改每个容器的/etc/resolv.conf文件实现)。pod是否使用内部的DNS服务器根据spec.dnsPolicy决定。
创建service时会自动地创建DNS记录,DNS里会记录和service关联的所有pods的IP。这一特性非常的有用,比如如果你想要在prometheus里监听某个daemonset,那么就可以为这些daemonset配置一个svc,然后让prometheus通过dns_sd_configs(基于DNS的服务发现)去自动发现所有的daemonset pods。
5.2 连接集群外部的服务 132
5.2.1 介绍服务 endpoint 133
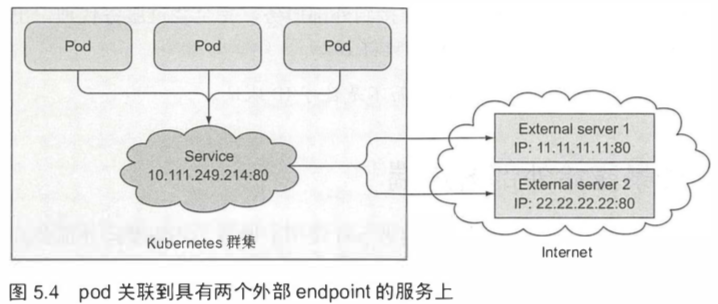
服务并不是和 pod 直接相连的。有一种资源介于两者之间——它就是Endpoint资源。
service创建endpoint,并且将流量导向 endpoint。
Pods expose themselves through endpoints to a service.
5.2.2 手动配置服务的 endpoint 133
尽管在spec服务中定义了pod选择器,但在重定向传入连接时不会直接使用它。相反,选择器用于构建IP和端口列表,然后存储在Endpoint资源中。当客户端连接到服务时,服务代理选择这些IP和端口对中的一个。
selector用于构建endpoint,svc直接从endpoint中选择一个地址来使用。
1 | apiVersion: v1 |
5.2.3 为外部服务创建别名 135
要创建一个具有别名的外部服务的服务时,将创建service资源的type字段设置为ExternalName。
1 | apiVersion: v1 |
5.3 将服务暴露给外部客户端 136
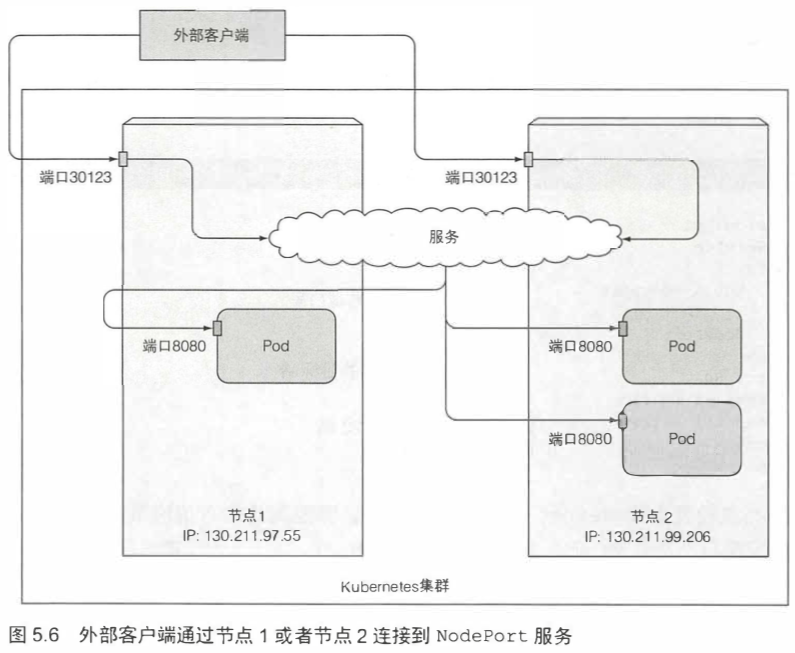
5.3.1 使用 NodePort 类型的服务 137
通过创建NodePort类型的服务,可以让k8s在其所有节点上保留一个端口(所有节点上都使用相同的端口号),并将传入的连接转发给作为服务部分的pod。
1 | apiVersion: v1 |
EXTERNAL-IP列显示nodes,表明服务可通过任何集群节点的IP地址访问。

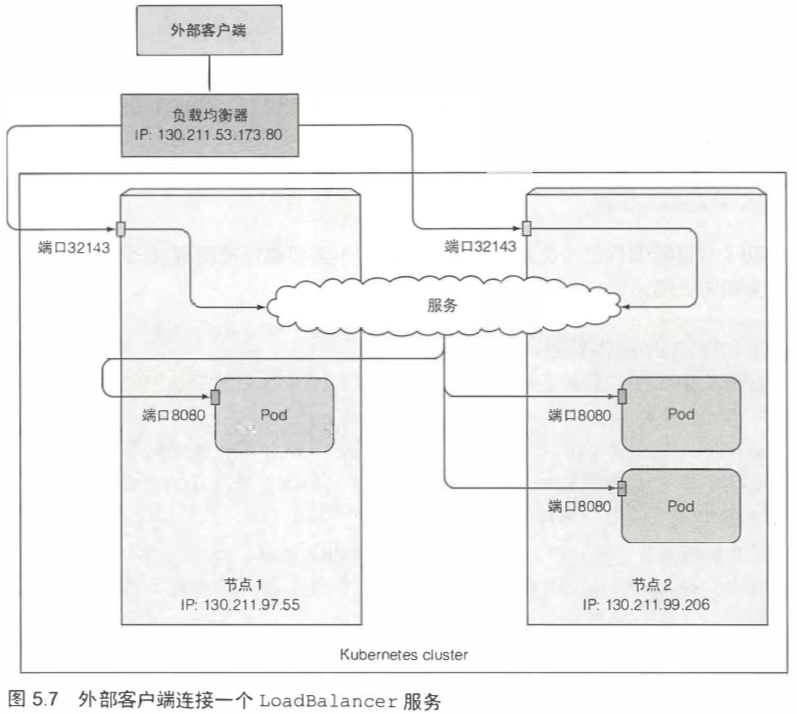
5.3.2 通过负载均衡器将服务暴露出来 140
在EKS或GKE等云端使用k8s服务时,可以将服务的类型设置成LoadBalance,直接将服务绑定到云上的lb上。
1 | apiVersion: v1 |
EXTERNAL-IP列显示的是lb的IP,可以通过该IP访问服务。

5.3.3 了解外部连接的特性 142
可以通过将服务配置为仅将外部通信重定向到接收连接的节点上运行的pod来阻止此额外跳数。这是通过在服务的spec部分中设置externalTrafficPolicy字段。
1 | spec: |
5.4 通过 Ingress 暴露服务 143
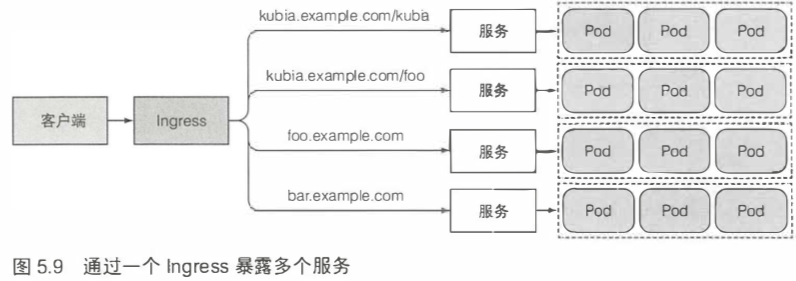
除了NodePort和LoadBalance这两种向集群外部的客户端公开服务的方法,还有一种方法,创建Ingress资源。
每个LoadBalancer服务都需要自己的负载均衡器,以及独有的公有 IP 地址,而 Ingress 只需要一个公网IP就能为许多服务提供访问。
Ingress在HTTP层工作,可以提供服务不能实现的功能(service在TCP/UDP层工作)。比如基于cookie的会话亲和性(session affinity)等功能。
Ingress其实就是集群的网关,一般都会使用Nginx或HAProxy,通过绑定虚拟主机的形式暴露集群内的服务。
5.4.1 创建 Ingress 资源 145
1 | apiVersion: extensions/v1beta1 |
定义了一个单一规则的Ingress,确保Ingress控制器收到的所有请求主机kubia.example.com的HTTP请求,将被发送到端口80上的kubia-nodeport服务。
5.4.2 通过 Ingress 访问服务 146
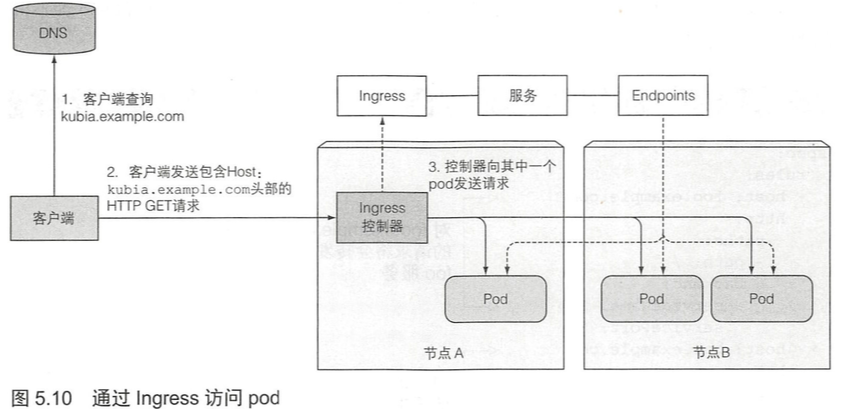
客户端通过Ingress控制器连接到其中一个pod的流程:
- 客户端首先对
kubia.example.com执行DNS查询,得到Ingress控制器的IP。 - 客户端然后向Ingress控制器发送HTTP请求,并在HTTP header指定host(
-H "Host: kubia.example.com")。 - Ingress控制器从该头部确定客户端目标访问哪个service。
- 通过与该service关联的endpoint对象查看pod IP。
- 将客户端的请求转发给其中一个pod IP。
curl http://kubia.example.com(需要在/etc/hosts添加192.168.99.100 kubia.example.com)和curl http://192.168.99.100 -H "Host: kubia.example.com"均可用来通过Ingress访问服务。
5.4.3 通过相同的 Ingress 暴露多个服务 147
一个Ingress可以将多个主机和路径映射到多个服务。
- 将不同的服务映射到相同虚拟主机的不同路径
1 | ... |
- 将不同的服务映射到不同的虚拟主机上
1 | ... |
5.4.4 配置 Ingress 处理 TLS 传输 149
将证书可私钥附加到Ingress控制器。
当客户端创建到Ingress控制器的TLS连接时,控制器将终止TLS连接。客户端和控制器之间的通信是加密的,而控制器和后端pod之间的通信则不是。运行在pod上的应用程序不需要支持TLS。
1 | apiVersion: extensions/v1beta1 |
5.5 pod 就绪后发出信号 150
5.5.1 介绍就绪探针 151
就绪探针(readinessProbe)会定期调用,并确定特定的 pod 是否接收客户端请求。当容器的准备就绪探测返回成功时,表示容器已准备好接收请求。
和存活探针一样,就绪探针也有三种类型:
- Exec
- HTTP GET
- TCP
就绪探针与存活探针最重要的区别是,如果容器未通过准备检查,则不会被终止或重新启动,只是从服务中删除该pod,如果pod再次准备就绪,则重新添加pod到服务。
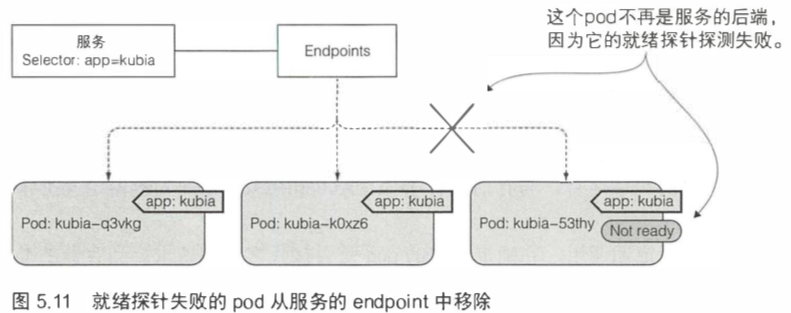
如果一个pod的就绪探测失败,则将该容器从端点对象中移除。连接到该服务的客户端不会被重定向到pod。这和pod与服务的标签选择器完全不匹配的效果相同。
5.5.2 向 pod 添加就绪探针 152
1 | apiVersion: v1 |
5.5.3 了解就绪探针的实际作用 154
应该通过删除pod或更改pod标签而不是手动更改探针来从服务中手动移除 pod。
应该始终定义一个就绪探针,即使它只是向基准URL发送HTTP请求一样简单。
5.6 使用 headless 服务来发现独立的 pod 155
如果告诉k8s,不需要为服务提供集群IP,则DNS服务器将返回pod IP而不是单个服务IP。
将服务spec中的clusterIP字段设置为None会使服务成为headless服务,因为k8s不会为其分配集群IP,客户端可通过该IP将其连接到支持它的pod。
通常情况下,DNS查询svc会返回svc的clusterIP。而对于headless服务,DNS查询会返回一系列A记录,分别对应相应的pod的地址。
5.6.1 创建 headless 服务 156
1 | apiVersion: v1 |
5.6.2 通过 DNS 发现 pod 156
非headless服务返回的DNS是服务的集群IP。
headless服务返回的DNS是所有就绪的pod的IP。headless服务依然提供跨pod的负载均衡。
5.6.3 发现所有的 pod——包括未就绪的 pod 157
通过添加annotations,可以将所有匹配标签选择器的pod添加到服务中。
1 | kind: Service |
5.7 排除服务故障 158
- 确保从集群内连接到服务的集群IP,而不是从外部。
- 不要通过ping服务IP来判断服务是否可访问(服务的集群IP是虚拟IP,是无法ping通的)。
- 如果已经定义了就绪探针,请确保它返回成功;否则该pod不会成为服务的一部分。
- 要确认某个容器是服务的一部分,请使用
kubectl get endpoint来检查相应的端点对象。 - 如果尝试通过FQDN或其中一部分来访问服务(例如
myservice.mynamespace.svc.cluster.local或myservice.mynamespace),但不起作用,请查看是否可以使用其集群IP而不是FQDN来访问服务。 - 检查是否连接到服务公开的端口,而不是目标端口。
- 尝试直接连接到pod IP以确认pod正在接收正确端口上的连接。
- 如果甚至无法通过pod的IP访问应用,请确保应用不是仅绑定到本地主机。
5.8 本章的k8s命令 159
1 | ########## Service ########## |
6 卷 :将磁盘挂载到容器 161
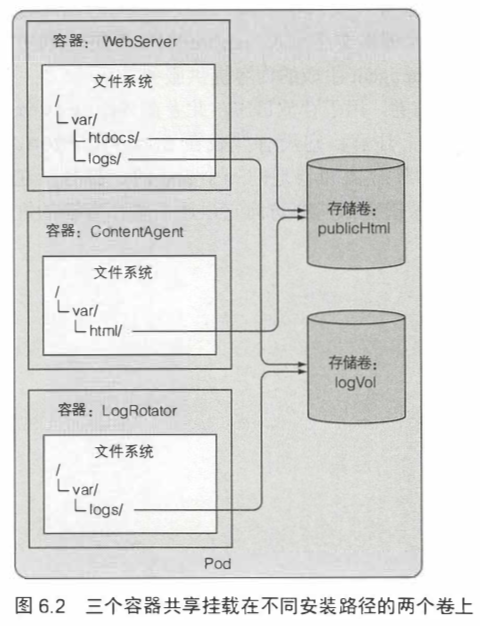
pod中的每个容器都有自己的独立文件系统,因为文件系统来自容器镜像。
k8s通过在pod中定义卷,使得存储持久化,和pod共享生命周期,而不会随着容器的重启消失。
6.1 介绍卷 162
6.1.1 卷的应用示例 162
卷被绑定到pod的lifecycle中,只有在pod存在时才会存在,但取决于卷的类型,即使在pod和卷消失之后,卷的文件也可能保待原样,并可以挂载到新的卷中。
6.1.2 介绍可用的卷类型 164
- emptyDir:用于存储临时数据的简单空目录。
- hostPath:用于将目录从工作节点的文件系统挂载到 pod 中。
- gitRepo:通过检出 Git 仓库的内容来初始化的卷。
- nfs:挂载到 pod 中的 NFS 共享卷。
- 云磁盘
- gcePersistentDisk
- awsElasticBlockStore
- azureDisk
- 网络存储
- cinder
- cephfs
- iscsi
- flocker
- glusterfs
- …
- k8s 内部资源卷
- configMap
- secret
- downwardAPI
- persistentVolumeClaim:动态配置的持久存储
6.2 通过卷在容器之间共享数据 165
6.2.1 使用 emptyDir 卷 165
1 | apiVersion: v1 |
可以指定用于emptyDir的介质。
1 | volumes: |
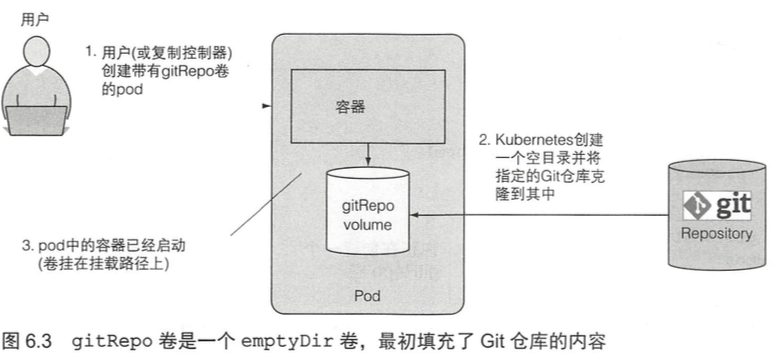
6.2.2 使用 Git 仓库作为存储卷 168
将拉取的git repo作为文件系统,可以方便的读取到git的内容。
缺点是,在创建gitRepo卷后,它并不能和对应repo保持同步。
可以使用sider容器进行「git sync」。
如果想要将私有的Git repo克隆到容器中,则应该使用gitsync sidecar或类似的方法,而不是使用 gitRepo卷。
1 | apiVersion: v1 |
6.3 访问工作节点文件系统上的文件 171
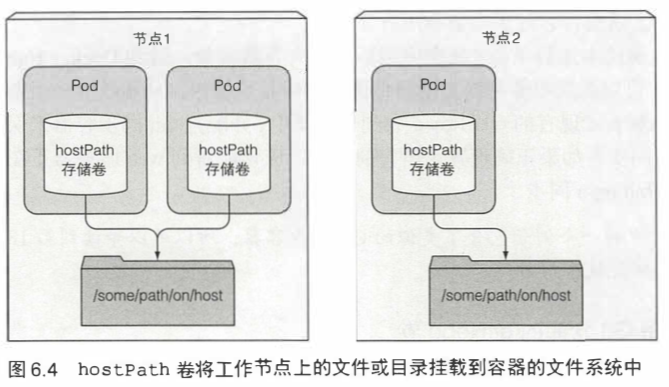
6.3.1 介绍 hostPath 卷 171
hostPath卷指向节点文件系统上的特定文件或目录。
6.3.2 检查使用 hostPath 卷的系统 pod 172
仅当需要在节点上读取或写入系统文件时才使用hostPath,不能用来持久化跨pod的数据。
6.4 使用持久化存储 173
6.4.1 使用 GCE 持久磁盘作为 pod 存储卷 174
1 | apiVersion: v1 |
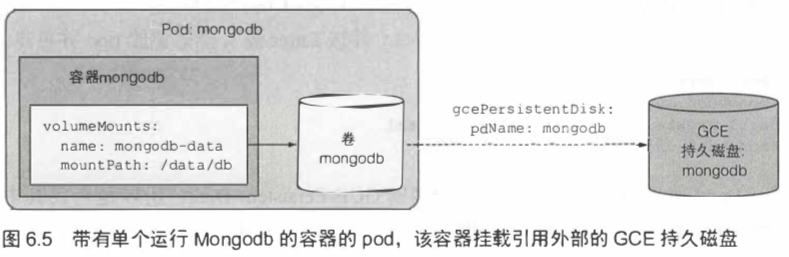
6.4.2 通过底层持久化存储使用其他类型的卷 177
- 使用AWS弹性块存储卷
1 | ... |
- 使用NFS卷
1 | ... |
6.5 从底层存储技术解耦 pod 179
将这种涉及基础设施类型的信息塞到一个pod设置中,意味着pod设置与特定的k8s集群有很大耦合度。这就不能在另一个pod中使用相同的设置了。所以使用这样的卷并不是在pod中附加持久化存储的最佳实践。
理想的情况是,在k8s上部署应用程序的开发人员不需要知道底层使用的是哪种存储技术,同理他们也不需要了解应该使用哪些类型的物理服务器来运行pod,与基础设施相关的交互是集群管理员独有的控制领域。
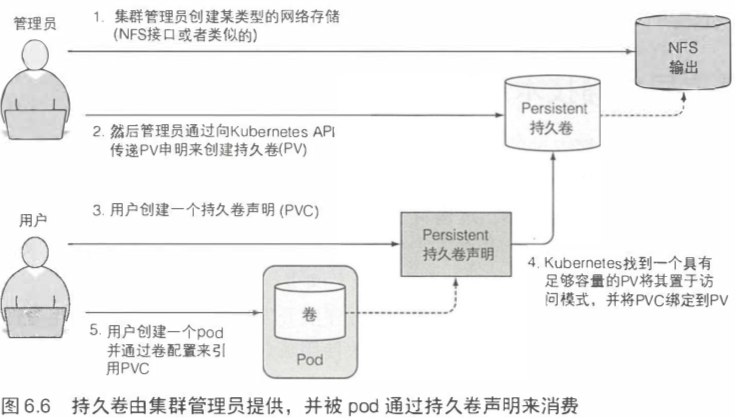
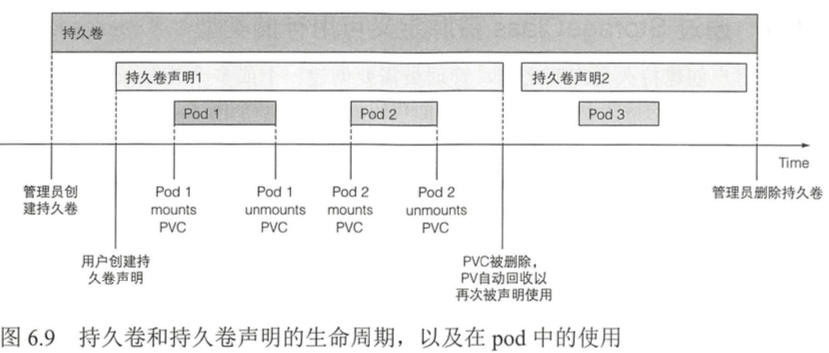
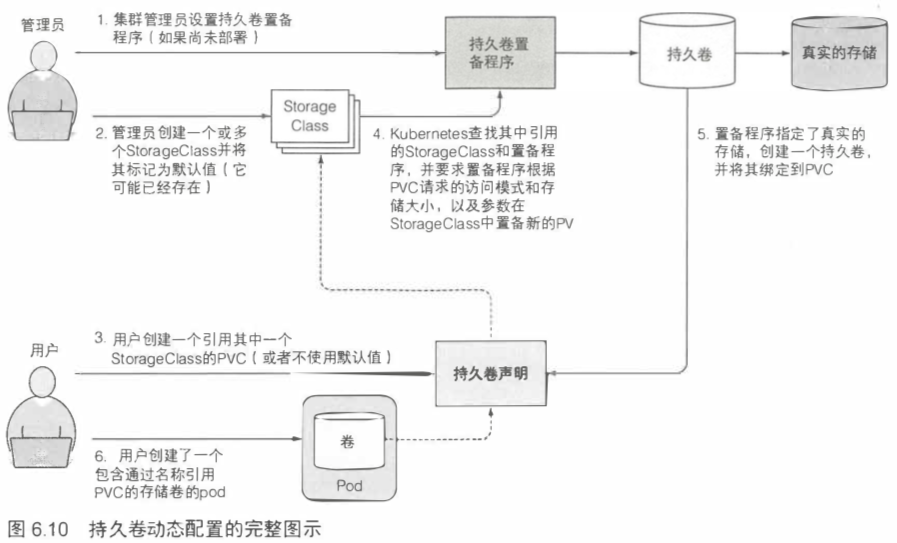
6.5.1 介绍持久卷和持久卷声明 179
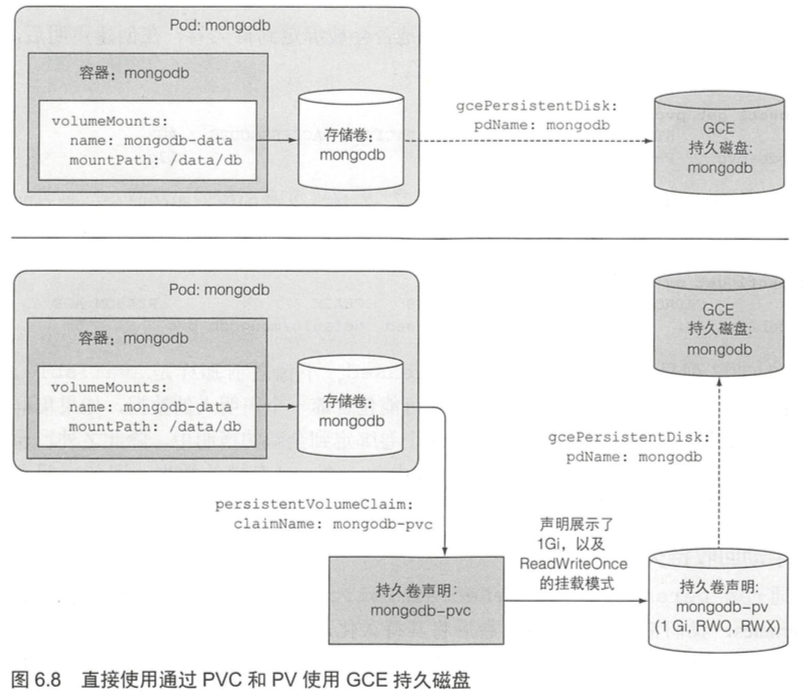
系统管理员首先准备好磁盘资源,然后创建全局的持久卷(Persistent Volume)。
然后用户通过创建持久卷声明(PersistentVolumeClaim,简称PVC)清单,指定所需要的最低容量要求和访问模式,然后用户将持久卷声明清单提交给k8s的API服务器,k8s将找到可匹配的持久卷并将其绑定到持久卷声明。
持久卷声明可以当作pod中的一个卷来使用,其他用户不能使用相同的持久卷,除非先通过删除持久卷声明绑定来释放。
6.5.2 创建持久卷 180
创建持久卷
1 | apiVersion: v1 |
在pod卷中引用GCE PD
1 | spec: |
在创建持久卷时,管理员需要告诉k8s其对应的容量需求,以及它是否可以由单个节点或多个节点同时读取或写入。管理员还需要告诉k8s如何处理PersistentVolume(当持久卷声明的绑定被删除时)。最后,无疑也很重要的事情是,管理员需要指定持久卷支持的实际存储类型、位置和其他属性。
持久卷不属于任何命名空间,它跟节点一样是集群层面的资源。
6.5.3 通过创建持久卷声明来获取持久卷 182
创建持久卷声明
1 | apiVersion: v1 |
当创建好持久卷声明,k8s就会找到适当的持久卷并将其绑定到声明,持久卷的容量必须足够大以满足声明的需求,并且卷的访问模式必须包含声明中指定的访问模式。
访问模式:
- PWO: ReadWriteOnce,仅允许单个节点挂载读写;
- ROX: ReadOnlyMany,允许多个节点挂载读;
- RWX: ReadWriteMany,允许多个节点挂载读写。
accessModes设置的是同时使用卷的工作节点的数量,而非pod的数量。
6.5.4 在 pod 中使用持久卷声明 184
1 | apiVersion: v1 |
6.5.5 了解使用持久卷和持久卷声明的好处 185
6.5.6 回收持久卷 186
通过将persistentVolumeReclaimPolicy设置为Retain从而通知到k8s,希望在创建持久卷后将其持久化,让k8s可以在持久卷从持久卷声明中释放后仍然能保留它的卷和数据内容。手动回收持久卷并使其恢复可用的唯一方法是删除和重新创建持久卷资源。
存在两种其他可行的回收策略:Recycle和Delete。第一种删除卷的内容并使卷可用于再次声明,通过这种方式,持久卷可以被不同的持久卷声明和pod反复使用。
6.6 持久卷的动态卷配置 187
6.6.1 通过 StorageClass 资源定义可用存储类型 188
1 | apiVersion: storage.k8s.io/v1 |
6.6.2 请求持久卷声明中的存储类 188
StorageClass资源指定当久卷声明请求此StorageClass时应使用哪个置备程序来提供持久卷。StorageClass定义中定义的参数将传递给置备程序,并具体到每个供应器插件。
简单地说,管理员可以手动通过置备程序创建PV,或者直接创建对应的StorageClass,然后用户创建PVC时,会自动根据StorageClass的设置调用置备程序创建出可供使用的PV。
1 | apiVersion: v1 |
StorageClasses的好处在于,声明是通过名称引用它们的。因此,只要StorageClass名称在所有这些名称中相同,PVC定义便可跨不同集群移植。
6.6.3 不指定存储类的动态配置 190
1 | apiVersion: v1 |
6.7 本章的k8s命令 193
1 | ########## PersistentVolume ########## |

